本文是我与NLP相识七年的经历和心态的转变。
前几日与友人在北京一个盲人捏脚店讨论其关于AR创业的想法和一些尝试。到临别回家路上,聊起我是否有创业的想法,有没有自己特别想做的事情,还聊起16年在浙大本科时期做的一个为视觉障碍人群的深度视觉问答系统,说当时他曾以这个项目为标杆,认为我们自始至终就这一个项目反复参加各种创业创新比赛,拿过不少奖,在当时已经算是很成功了。此时我不禁汗颜,因为当时VQA技术还处于刚新萌芽,深度学习处于蓬勃发展的初期,拿着现在看起来非常“low”的技术到处“招摇撞骗”的我并不觉得有太多可夸傲的东西。
但在十字口的岔道分离后的那个晚上,我失眠了。这几年的经历和想法如潮水一般涌来,让我不禁想起做这个项目前的一些懵懂的想法,以及我脑中幻想的拼图。突然回首,发现这些年来这个拼图尽管越来越模糊,但等擦干净看时却已经一块一块拼接起来了,这无疑是最让人振奋的事情。
幻想萌芽
标题中写到“七年”,因为我是15年正式接触到机器学习,开始入门AI与NLP的。但早在2012年,我在看一部名叫《樱花庄的宠物女孩》的新番时,我就对当时一名角色赤坂龙之介独立开发的“小女仆”产生了极大的兴趣,这是龙之介独立开发的一个拟人型助手,能够帮他处理一些联络事宜。当然真正吸引我的并不是这种类似“转发邮件”的功能,而是它的一些拟人型动作、对话甚至对龙之介的喜欢和对其它异性的敌意。

当时我不禁在想,是否有朝一日,每个人是否也能有属于自己的二次元“伙伴”,能够感知到人类的情感,能够自由地进行对话。我相信,时至今日,这也是很多同学进入人工智能,学习自然语言处理(NLP)的梦想吧。
所以我在高考结束之后,在家人的支持下,选择入学浙江大学的工科(信息)大类。
幻想冲击
要说因为一部动漫的幻想小火苗,就决定了我未来主修计算机科学与技术的话,也是有些过于罗曼蒂克。当时浙大计科还处于将兴未兴的状态,选专业的均绩几乎与前几年一直位居第一的自动化(控制)相近,由于我极度讨厌学化学课,才是“误”入了计算机专业。
在2015年我看了 《Her》 这部电影,直接催发了我当时就想研究人工智能相关理论和应用的想法。影响到后续的何志均班申请和选导、研究生方向的选择、实习和未来工作的选择。《Her》讲述的是AI系统OS1化身的虚拟助手Samantha(漫威寡姐配音)与男主Theodore(也是DC小丑饰演者)的爱情故事。电影里Samantha美妙的声线、拥有独立思考和情感表达能力以及不断进化的智能给了我不少的思想冲击,同时我也对如此智能的人机交互产生了极强的向往。

至今我还沉迷于这样的幻想中,幻想有一天机器能跟人产生情感上的共鸣。其间,我翻阅了大量人工智能的资料,了解了机器学习,学习Python,在何志均班面试过程中一再强调自己的研究志向和想法,联系到了今后对我影响非常大的 蔡登 老师。
模式识别
2015年,和当时大多数人一样,我通过Andrew Ng老师的Coursera课程入门机器学习,同时进入蔡登老师的实验室(浙大CAD&CG机器学习组)进行实际项目的探索,当时蔡老师想让我去接触一下当时实验室的一个重要项目“车牌自动识别”,但被我婉拒了,因为当时刚被《Her》激发的我对这种“图片识别”并不是非常感兴趣,一意想做NLP方向,由于实验室NLP相关的项目并不多,他便让我旁听了社交网络与数据挖掘小组的组会。
在这个组会中,认识了不少优秀的学长,这些学长们后来有的出去深造(CMU、UIUC等)、有的加入了如苹果阿里等行业领先的公司、有的甚至创业并拿到了浙江省万人计划。在他们的帮助下,我逐渐入门了数据挖掘与NLP,并做了一个评论情感分析(Sentiment Analysis)项目。当时对AI与机器学习认知并不深的我,做这个项目前那个晚上几乎就兴奋地失眠了,失眠的原因是在构想自己创造的“人工智能体”,当时我想,要想然机器能够正常与人交流,其流程中需要很多模块,情感分析来判断你是高兴还是不高兴自然是非常重要的,我甚至在脑海里画了一个“人工智能体”大脑的流程草图,恨不得赶紧下床去coding。
在学习了NLP相关基础后,我便拿着从Kaggle上下载的数据,看着各种教程,训练模型,预测结果,期间我也接触到了当时大热的Word2Vec,并自己训练了一批词向量。这个项目花费了我一定的时间,我最后做完各种实验,在自学了Latex之后拿着一篇论文依样画葫芦般地写了一份研究报告,交付给了蔡老师,他也还是比较满意并同意了我申请他做本科生导师。
虽然看起来很是圆满,但是有几点是令我失望的:一是我发现我的模型完全就是实验性质,如果我输入一句自己撰写的话,输出多半是错误的,二是如果我想使用我的母语中文,模型是不可能预测出来的,这与我心目中的“情感分析”机器相差甚远。当时稚嫩的想法其实也多少映射着现在自己的忧虑,即靠纯数据驱动的学习方式得到的模型或者系统真的能够理解我们的话吗?现在的方法是不是太依赖于数据了?这种模式识别的方法真的是我们想要的吗?
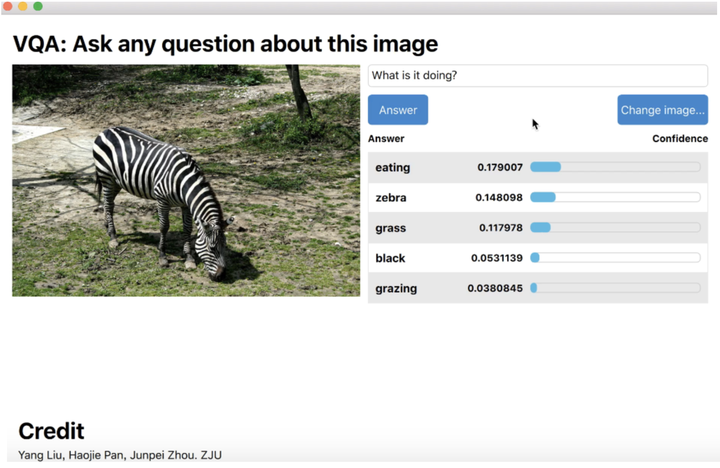
16年的寒假,我因一些机缘巧合与沛神和洋腿认识,一起做了导语中所说的VQA项目。现在想来,能遇到这么给力的两位队友实在是大学时代的一件幸事。沛神拥有极其可怕的综合素质,修的学分是我的1~2倍却能一直稳居计院第一,学习、社团、科研、比赛一个不拉,在CMU LTI毕业后,目前在Google Cloud做机器翻译;洋腿比我更早(大一)就进入了AI领域,研究兴趣是计算机视觉,在14、15年那种深度学习框架特别难用的时代,自己手撸了CNN网络,目前在我的强力推荐下去了蔡登老师实验室读PHD。在本科的后来几年中,我们几乎是合作最紧密和通顺的“黄金铁三角”。
VQA的想法是我在与沛神讨论一个校级科研项目的时候找到的一个idea,然后恰好当时训练过Word Embedding,找到了做CV的洋腿,没过一个月就把Demo做出来了,并斩获国创、挑战杯等各种项目的立项,最终在很多创业创新比赛和项目中取得了比较好的成绩,做了不少demo也申请了专利。
VQA项目确实也是我想实现的AI蓝图中的很小的拼块,因为《Her》中的Samantha也需要有一个摄像头作为她的眼睛来与Theodore进行交流,只是凭借当时的技术,我们只能勉强基于一些Pattern Recognition方式去实现所谓的“智能”,这也同样是当时令我失望的一个点,因为我发现当时很多所谓的人工智能,都只是简单的模式识别罢了。
文本生成
回顾我本科的最后一年半,因为抽出了大量时间可以做一些想做的事情,我真正(从某种程度)上踏入了智能对话与人机交互的大门,17年下旬到18年上旬,从网易游戏伏羲实验室到阿里达摩院的实习经历,从理论到实践再到学术,从满怀憧憬到失望到回归平静,“文本生成”这个方向贯穿了这一整年。 当时的伏羲实验室还是非常小的团队,NLP的成员只有三个人,当时我们探索过很多文本生成方向,包括简历筛选理由生成、智能台本生成、智能NPC等落地当时都无疾而终,在实习期间,也不止一次感到迷茫。另一方面,被自己的一种“急切想要一篇论文”的思绪所主导,最终开始踏入对话生成的一些研究工作,当时在伏羲与赵洲老师的合作中,做了两件事情,分别是 对话摘要(Dialogue Summarization) 和 对话应答生成(Dialogue Response Generation),前者是我的第一篇顶会论文(WWW’19,链接)的topic,实现了我科研上从零到一的突破,后者是我浙大的学士论文。
大四的下学期,我在蔡老师的推荐下去了达摩院NLP组(司罗老师组),研究天猫多评论摘要(Multi-review Summarization)的课题,这是我第一次接触工业界巨大规模的数据,提纯并使用文本生成的技术去为用户创造价值(提升用户阅读评论的效率),最终兜兜转转发表在了 SIGIR Industry Track中(链接)。 我还记得,当我实现第一个Seq2seq模型,第一次看Memory Network论文时的那种欣喜感,并认为在大量对话数据下,用Memory的手段解决对话的长期依赖问题,再基于对话生成功能,就真的能初步实现一定程度上的“智能体”,能够流畅地与人进行对话。然而随着我对文本生成任务越来越熟悉,发现与我所想的还是相距甚远,当时流行用Memory或者Attention的手段将前文信息总结到一个向量中,再加入到Seq2seq模型进行生成的任务,这种隐式的记忆并不能很好地捕获用户输入的真实意图以及与前文的关系,同时基于Beam Search的概率生成在当时往往在流畅度上做的并没有特别好,也经常会生成一些前言不搭后语的话,缺乏逻辑的严谨性。此外,文本生成模型通常在一些高度对齐的任务(如机器翻译、ASR等)能表现出强大的优势,在需要多样性的对话过程中,却经常产生千篇一律的回答。
这也是我研究生包括后续工作以后企图通过知识的手段来解决这些问题的一部分初衷。
世界知识
我与我的导师Yangqiu Song教授是通过邮件认识的,当时他刚从WVU到HKUST CSE担任助理教授,我在网络上看到他的主页,试图通过邮件申请过去做暑期的RA,不曾想他爽快地答应了,甚至通过系里给了我 $10,000 HKD 每月工资作为在香港的生活费。
当时做的是NIST发布的一个LoReHLT评测,主要研究自动将一个在一些罕见语言(如提格里尼亚语, 奥罗莫语,维吾尔语等)地区灾难新闻中抽取情景帧句子,并判断是否这个新闻里是否有一些”issue’‘和”need’‘。在这样的任务下,我第一次意识到了堆数据训练深度模型不是万能的,还需要一些语言学,如Morphology,以及迁移学习如Domain Adaptation的重要性。后续我与Yangqiu沟通后,决定去HKUST读硕士并从事关于世界知识(World Knowledge)和常识(Common-sense)的一些研究工作,去香港之前,我对导师与Dan Roth在arxiv发表的《Machine learning with world knowledge: The position and survey》进行了翻译工作,并对引入外部知识或者远程监督(Distant-Supervision)知识来辅助模型学习有了一些想法。
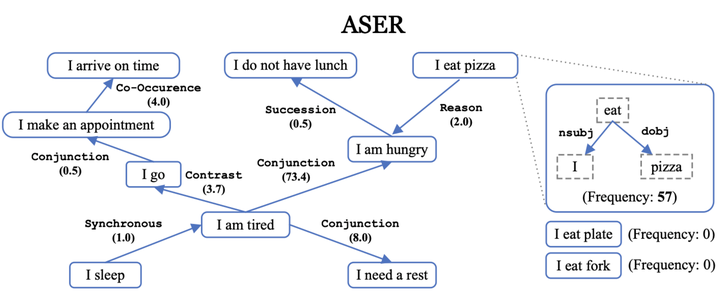
在18年下旬加入HKUST KnowComp小组后,因为我之前有一些对话相关工作,师兄Hongming向我和同届的Xin提出合作 ASER 的想法。ASER(Activities, States, Events, and their Relations) 是Yangqiu在华为诺亚方舟时候就很想做的一个事情,前身为ActivityNet。这一个大规模的事件知识图谱,与当时市面上的一些知识图谱不一样的是,每个节点是一个事件(Eventuality),而不是实体,我们希望通过大规模的数据挖掘出每个事件元之间的关系,目前已经有4.38亿的Eventuality和 6.48 亿的边。ASER是HKUST KnowComp也是Yangqiu的一个Lifelong的工作,我很有幸能够成为初始成员之一,并与实验室两位优秀的人成为了战友。在ASER的第一篇论文中稿 WWW’ 20 [链接] 之后,我们仍然在不懈地在ASER这个初版雏形体系下不断地有一些新的思考,在19~21年我们提出了ASER2.0 ,我对ASER做出了一版简易的概念化模块,并搭建了Demo。
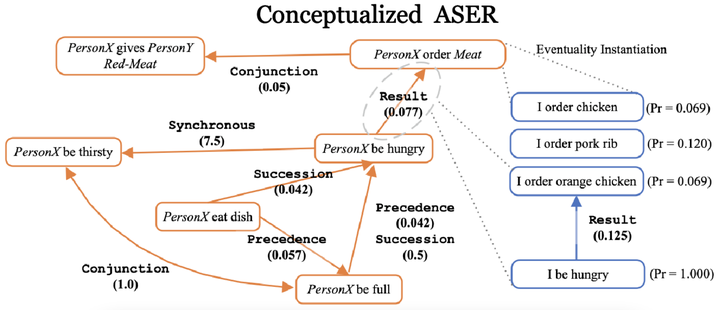
通过ASER这个项目,让我惊喜地发现常识知识是如此有魅力,并且我认为背景知识绝对是我拼图中的一部分,Samantha之所以能有如此高的智能其中一点也是因为不断地学习人类沉淀了千百年的背景知识,才知道这个世界上什么是男人和女人、为什么天黑了要睡觉。 除却ASER这个令人回味无穷的项目以外,还有我的硕士毕业论文也是让我和Yangqiu非常激动和废寝忘食的一个Topic,其源头是我 AAAI’19 被拒的一篇基于 Caption和VisualDialogue 的一篇Dialogue Summarization 论文,我们惊喜地发现,通过图片建立起对话和描述间的关系,竟然可以把一些人类语言学的更深层次知识给挖掘起来,因此我们花了很长的时间去研究语用学(Pragmatics),以及对应的两个子概念:
- Implicature:“小A会参加这次聚会嘛”“她家里有事” → “小A不会参加这次聚会”
- Presupposition:“我不想再去这家餐厅了” → “我曾经去过这家餐厅”
这个研究对我来说是非常exciting的,我常给人举得例子就是“假如你女朋友发了‘我睡了!’”意味着她是真想睡觉了,还是生气了(这在日常生活中经常会碰到lol)。当然我们的研究成果并不被大多数ACL与EMNLP的语言学专家认可,认为我们是半吊子的语言学出家(确实也是),最终在我毕业多轮投稿后,还是在学弟Tianqing的帮助下以Dialogue Summarization为主题发表在了AKBC’21 (链接)上 我研究生的这段经历,让我以非常舒畅的状态对世界知识、常识与语言学有了更深的了解,绝对是我拼图中非常浓墨重彩的一笔。当然,因为当时醉心于世界知识的构建,错过了NLP十年难遇的突破性工作——大规模预训练语言模型(PLM)。
业界落地
从15年下半旬到19年下半旬,经历了4年技术的打磨、沉淀和对NLP的理解,我面临了人生的重要拐点,是直接就业,还是继续读PHD?这个问题也困扰着成千上万的同学。我再三对自己进行了剖析,认为自己不是那种对特定领域科研深耕型的人,更系统性地做出产品和应用,甚至做出我幻想的最终态能给我带来更大的成就感。
因此借着想学习和建立工业界级应用落地的由头,加上仰慕贾扬清老师,我加入了阿里云计算平台,在PAI机器学习做大规模迁移学习框架的开发,并落地了不少应用。不过误打误撞的是,因为预训练语言模型的热潮,我们迁移学习/NLP组集体转向了这个方向,使得我对BERT以及后来的一大堆PLM有了非常深入的了解,加上很早前就有传来GPT-3在文字生成上取的的一系列重大突破,让我对其产生了更大的兴趣。
我在阿里的工作主要聚焦在 EasyTransfer 这个框架的开发(目前已开源),对集团内(如天猫、咸鱼、优酷)算法同学提供大规模高性能的迁移学习(包括PLM)分布式训练与预测,对集团外的客户进行NLP产品化解决方案的定制。同时这一年也是我论文井喷的一年,先前学生时代的遗留工作基本都纷纷中稿,在阿里Leader Minghui和同事 Chengyu 的帮助下也发表了人生第一篇ACL、EMNLP、CIKM,etc.
在阿里期间轻度参与的一个项目M6 (paper, 以及我做的产品体验链接)让我见识到了大规模多模态预训练模型的强大能力,并结交到了一作Junyang大佬。由此我也忍不住思考,我这些年来一心坚持做文本相关的工作,但文本是否足够能够表示世界知识,是否足够能够让一个智能体理解这个世界,理解人所说的话,人的所思所想以及复杂的情感?
怀揣着这样一个想法,再加上个人原因和工作地的变动,在与王仲远老师的几轮沟通下,我来到了北京,加入了快手多模态内容理解部门(MMU),希望能够通过快手百亿级别的视频与文本,理解人类知识,并探寻短视频时代下人类传播方式、知识媒介变化下世界知识的新的存在方式以及未来智能体所需的知识背景。
拼图重组
当然现实总不会总是罗曼蒂克,这几年来经历的风风雨雨也就自己心里清楚,甚至在很长一段时间内都已经忘记自己为什么学计算机,为什么做AI,为什么研究NLP和世界知识。每段经历都像一个个小碎片一般,散落在记忆的深处,但通过一些契机,将其重组之后,我清晰地感受到拼图逐渐被完善的快乐,可以很激动地跟友人分享说“原来我一直在路上啊”。而拼图描绘的画面越来越清晰之后,便产生了信仰,信仰给人带来的喜悦是无与伦比的。而我也很幸运能够遇上很多在这条路上陪伴着我的人,我的导师、各个项目的队友与合作者们、我的家人和朋友们。
至于未来,我会牢牢抓住这次拼图重组的机会,逐步去实现真正想实现的东西。最近看了很多目前很多智能体的消息,包括虚拟人与聊天机器人,包括元宇宙与人工智能,我很幸运能够在这个年代下,大家能一起做出这么一些有趣的事情。尽管现实与理想还很遥远,我还是相信在学界业界技术的快速演变,能够逐步接近初步的包含有世界知识、有自己人格和情感的智能体,并且如黑石一雄《克拉拉与太阳》中的陪伴机器人一样,对世界有强烈的好奇心、观察力和同理心(事实上,业界已经有一款虚拟聊天Bots能做得很好了)。在这之后我也会做一些初步性探索,如果有跟我有相同幻想的朋友,也可以与我交流 myscarletpan@gmail。
——辛丑年 腊月廿九 生日记