本文介绍了我对GPT使用工具的思考
ChatGPT出来也有好几个月了,从刚开始出来时我亲自体验后的感叹技术已经进步如斯,到后面它彻底变成现象级的话题,到前阵子亲自下场做LLM,发现每天的技术都在迭代,对LLM的认知也在不断迭代。迭代最为迅速、也是集体智慧最大体现的地方除了各种低成本复现以外,就是将GPT模型作为平台,在上面做Application了,知名的Notion、Jasper这样的软件已经能够月入百万刀。最近正好也是在参与相关的项目,结合一些迭代后的认知想聊一下LLMx工具这个方向。
我曾在我一年前的文章《我与NLP这七年》里回想起自己为什么做NLP研究,为什么这么想尝试让机器理解世界知识,但没想到世界发展如此快。AGI这个名词其实以前并没那么火,很多做NLP或者CV的同学也不会自诩自己是做AI的,感觉会显得像营销号和不够专业,但这一次ChatGPT的出现让这个名词火了起来,OpenAI创始人拥有的梦想也逐渐向全世界地影响开来。越来越多的志同道合的人聚集起来,最终朝着实现通用人工智能方向越来越近(当然也不排除走歪的可能性)。而通往这个方向,想构建一个World Model,GPT是一种方式,知识图谱是一种方式,可能也有千千万万其他方式,最近ChatGPT出来确实也让我兴奋了很久,感觉自己被推着朝想象中的方向又迈进了几步。
跟很多人的观点比较一致,我感觉ChatGPT表现的能力更像是“超人”而不是“拟人”,因为通常来讲人比起机器而言是比较“愚钝”的,并不会上知天文下知地理,一会能帮人写专业论文一会又能教人做菜。而人也通常记忆不是那么清楚,比如让我一个学了这么久计算机领域的同学去回忆一些有机化合物的分子式结构,大概率是记不得的。但是人比较难能可贵的品质,除了会说话,还有就是会思考了。GPT能够解决说话的部分,现在大家在研究的COT或者Instruction-tuning方向希望教会它能思考。但区分一个精明能干的同学和一个普通的同学,其实不用太考察知识量的多少,而是需要考察其“解决问题的能力”,也就是说,对于明显你不会的问题,比如口算一个24的阶乘,你能不能通过一步步演算,或者一步步使用工具去解决这个问题。今天想探讨的主题就是这个,AIx工具是否是未来比较可行的发展道路,亦或者说这才是实现AGI比较靠谱的方式,而不是将所有的知识都一股脑塞到一个特别大的脑子里。
事情还是得从ChatGPT出来之后网友发现的问题讲起,其中被指摘最严重的就是它一开始算术并不是很出色,有些回答缺乏事实性地一本正经胡说八道,时效要求高的问题也答不上。比如下面GPT-4的几个Case:
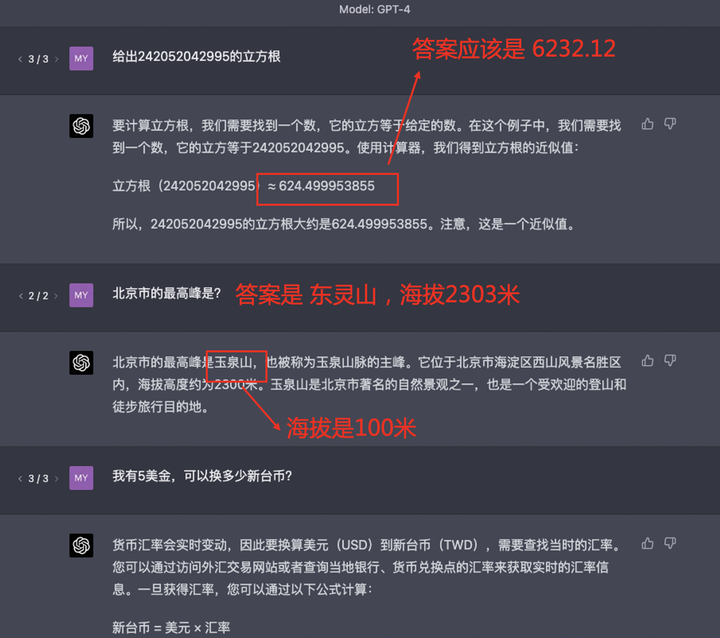
如果比较认同我上述的“超人”和“拟人”的思想的话,这几个case人们对它的预期都是超人,答不出来会让人很失望,因为希望机器在这种能够被自动化的算术、百科知识问答、汇率换算上能够表现出机器应有的才能。 那是否可以把GPT当成是一个会说话的人,或者说懂得一定方法论能解决问题的“拟人”形态呢?OpenAI的WebGPT[1]以及Meta最新发布的Toolformer[2]证实了这个思想,其实很简单,LLM不会的,让他自己去生成一些调工具的指令就可以了。我们还是以上述三个问题一一看下,调用工具的GPT是怎么做的:
1. 解数学问题:当LLM对于“给出242052042995的立方根”生成“242052042995的立方根是”的时候,我们希望它下一个生成的TOKEN是去调用工具获得回答,而不是直接生成“624.499”这样错误的答案。

2. 百科知识问答:当LLM对于“北京最高峰是?”问题生成“北京最高的山是”的时候,我们希望它的下一个生成的TOKEN区调用问答检索工具获得回答,而不是直接生成“玉泉山”这样的错误回答,如果它想补充信息(比如海拔),我们也希望它通过知识图谱中的严格信息进行工具调用生成。
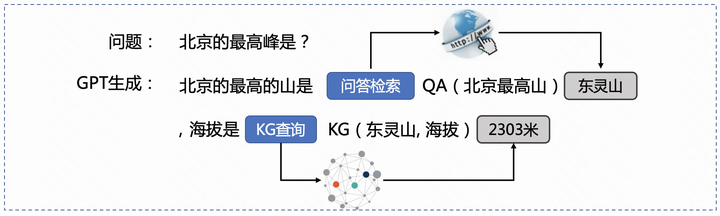
3. 汇率查询:这个也是显而易见了,先去搜汇率,再计算会比直接生成靠谱很多
那么这种GPT调用工具的方法到底是怎么实现的呢?用过New Bing的同学可能会发现,它会根据问题的不同去判断是否应该调用工具(即搜索一个或多个关键词),将搜到的文献片段进行引用。这个技术其实可以追溯到OpenAI发表的WebGPT技术。我这里简单做个介绍,WebGPT生成可以分为两个阶段:
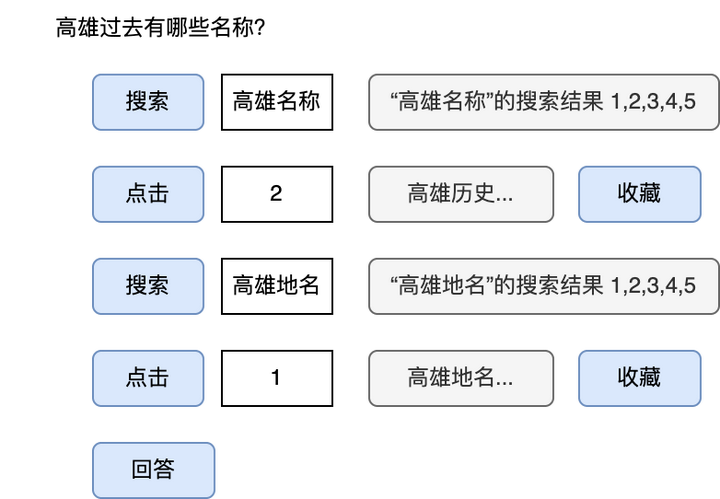
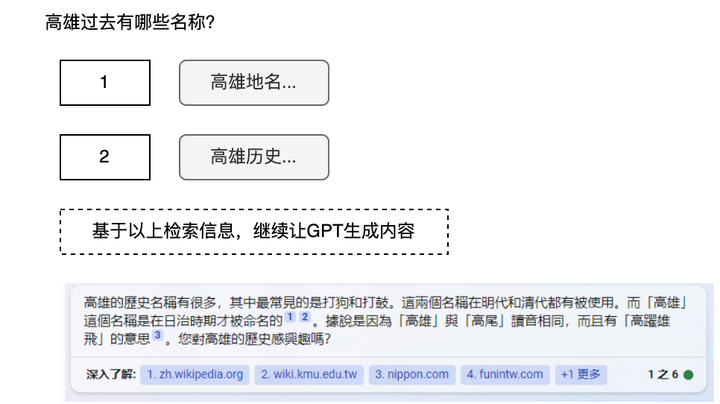
1. 准备资料阶段:输入为“高雄过去有哪些名称?”,蓝色方块代表特殊token,也是指令,首先GPT生成【搜索】这一特殊token,代表“搜索”这一命令,然后生成“高雄名称”,表示想要搜索这一query,然后搜索得到多个链接结果当作GPT的输出,例如有1到5五个链接。然后执行【点击】操作,具体点击第2个链接,然后将得到的页面内容当作GPT的输出,然后执行【收藏】操作,表示要将使用该内容。如此循环,最后得到【回答】操作,表示想要真正生成回答。
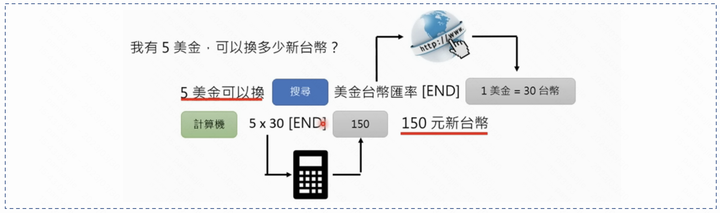
2. 生成回答阶段:将Query以及搜索得到的内容作为输入,然后继续让GPT生成内容,达到类似NewBing的效果,注意到,引用的角标大概率也是生成的。
上面是WebGPT在做inference时的具体流程,那它是如何训练的?它构造了一个指令数据集,通过让人在模拟的文本浏览器环境进行操作,将这些动作序列记录下来形成,动作转化为特殊token(即指令),检索内容转化为文本。由此只需要人在界面上操作,其所执行的各种搜索、点击、选取答案等动作都会被记录下来,最后转化为文本,构成数据集。最后用这个指令数据集来finetune GPT。
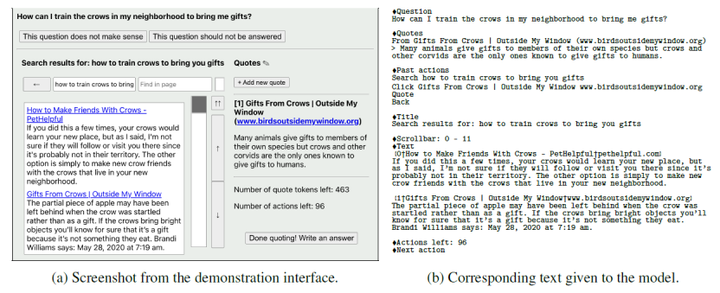
当然,这种方式实在太费人力了,人权主义者可能又要站出来抗议OpenAI雇佣廉价非洲工人。所以今年2月Meta发表了一篇名为 Toolformer 的论文,提出我可以用大模型(如GPT-3)来帮我做这个标注,只需要加入一些过滤规则就行,下面是Toolformer生成的一些“使用工具”的回答:

里面有涉及几个工具:
- QA():用Meta自家的基于检索的小样本LM QA生成库 Atlas,做一些检索式问答
- Calculator():用python实现的简单四则运算
- MT():会用到基于fastText的源语言检测,然后调用自家的NLLB去做翻译
- WikiSearch():使用了BM25检索出一些词的维基百科片段
- Calendar():获取当前时间
因此假如我们能够构建一定的指令数据集,能够在finetune后使得GPT生成“使用工具”的回答就好了,这个数据集他们通过调用GPT-3来进行自监督的方式生成:
1. few-shot样例生成:通过利用GPT-3的In-context Learning的手段,将一句正常话转成一句带有API调用的话。

2. 验证和过滤GPT3生成结果:核心思想是假如“带API调用的话”,比起“不带API调用的原话”,生成正确答案概率的要大,那这个生成结果大概率是置信的。
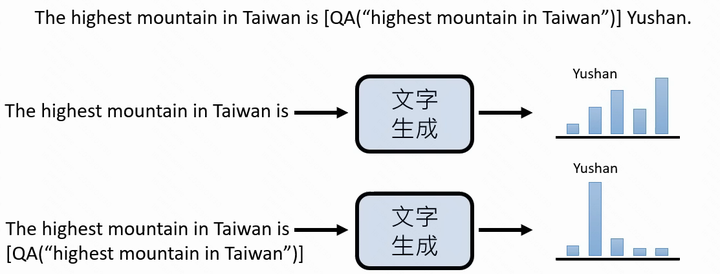
有了这些自动生成的指令pair,我们就可以用instruction finetuning的方法让我们的基础语言模型实现带有API回答的生成了,而Meta的研究者也做了充足实验,证明会用工具的GPT-J远远胜过不用工具的。
所以,到这里回过头思考的话,其实GPTx工具的训练方法本质跟InstructGPT的方法也差不多,都是去“蒸馏”(或者对齐)人类的行为(比如InstructGPT是人类生成“自然语言回答”的能力,GPTx工具是蒸馏人类“使用工具解决问题的能力”)。而Toolformer跟斯坦福Alpaca很类似,其实是蒸馏GPT-3“使用工具解决问题的能力”,而后者是蒸馏ChatGPT对问题生成“自然语言回答”的能力。 回到前头说的,实现一个world model,我们确实可以好好思考下,整个世界的知识、状态和环境,通过互联网进行了数字化编码,保持着高时效性的更迭,这真的是一个GPT可以装下的吗?会有一种mapping方式,将整个世界都压缩在神经网络里么?如果实现了这个,可能离AGI也不远了,但它将变成“超人”,人类物种存在的必要性是否还在呢? 扯远了哈哈,总结来看,通过GPT生成调用工具的指令,能够使得LLM具有更强大的与外部世界交互的能力,这里将会定义一系列生成模型的新范式,我认为中短期是一个非常有潜力的方向。
[1] Reiichiro Nakano, Jacob Hilton, Suchir Balaji, et al. WebGPT: Browser-assisted question-answering with human feedback. arxiv.2021
[2] Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, et al. Toolformer: Language Models Can Teach Themselves to Use Tools. arxiv. 2023
[3] Hung-yi Lee,【生成式AI】能夠使用工具的AI:New Bing, WebGPT, Toolformer. https://www.youtube.com/watch?v=ZID220t_MpI&t=1268s