本文是我对AI Agents方向的一些思考和总结。
前阵子一直在做AI Agents方向的工作,深度参与了Auto-GPT社区R&D team的设立和讨论,在公司内部也上线了自研的AI Agents平台,最近趁着项目阶段性汇报,整理了一下这个方向的一些技术和架构上的思考,以供大家参考。 我还维护了一个awesome的repo,专门记录当前此方向的研究路径、项目和相关工作,大家可以点个star,后续也会持续更新,也希望小伙伴们多多贡献!
AI智能体(AI Agents)方向不管是在开源、研究还是业界都是一个万众瞩目的方向,自从GPT-4问世以来,形态不断在进行更迭,当前阶段我们可以从三个维度观察 这个事情:
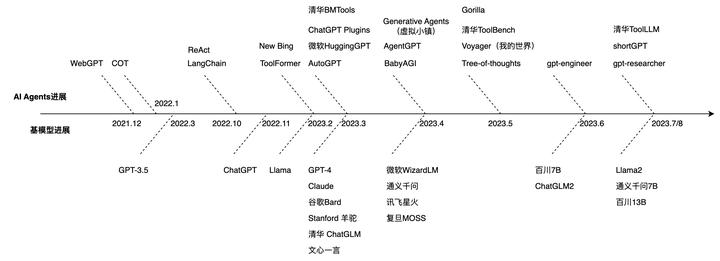
- 基模型的更迭:随着GPT-3.5的推出,到ChatGPT的爆火,到GPT-4的惊艳所有人,后续来自各个团队基座模型如井喷式发展,但个人认为实际上除了GPT-4等各别工作,大部分技术上依然沿用的是GPT-3.5(一年半前)的方案,进行数据上的迭代。
- 大模型使用工具:在ChatGPT出来之前,工具调用还停留在做搜索/知识问答阶段,如WebGPT、ReAct都是跟搜索引擎进行交互,今年2月份开始ToolFormer、HuggingGPT、ChatGPT Plugins等一系列工作的提出将这个方向推向了热门,后面的Gorilla、ToolBench和ToolLLM容纳的工具越来越多,越来越智能,比如最近清华刚提出的ToolLLM就包含了1.6w个现实世界的API
- AI智能体:在RL的智能体之后,WebGPT、ReAct可以说是基于LLM的AI智能体的雏形,确定了大模型规划任务-调用工具-反思的一整套框架,而AutoGPT的爆火将这一个范式推向了高潮,短短一个月在Github就有10w的star,研究者跟随着这类思路,提出了多智能体交互(Generative Agents)、Voyager(我的世界探索Agent)、gpt-engineer(项目研发Agent)、shortGPT(自动短视频剪辑Agent)、gpt-researcher(智能研究Agent),新的类型和范式在一时之间井喷式发展,Github Trending常年能看到这样的新项目。
因为该方向的相关工作其实很多变化很快,没有办法一一列举,如果有什么比较重要的工作缺失,辛苦评论区的小伙伴提醒一下。
技术路线
OpenAI的Lilian Weng在 LLM Powered Autonomous Agents 一文中基本将AI智能体的框架整理得非常顺畅了,强烈建议大家可以先去看这一篇文章以及相关的文献,下面是增加了自己的理解,稍微补充了一些的版本。
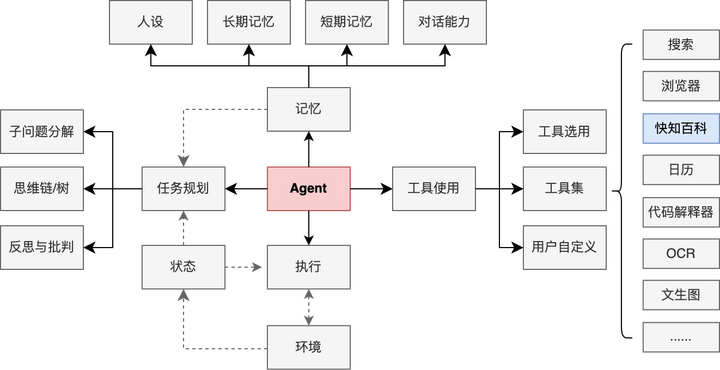
一、任务规划(Planning)
1. 复杂任务的子问题拆解
通常来讲,复杂任务不是一次性就能解决的,需要拆分成多个并行或串行的子任务来进行求解,任务规划的目标是找到一条最优的、能够解决问题的路线
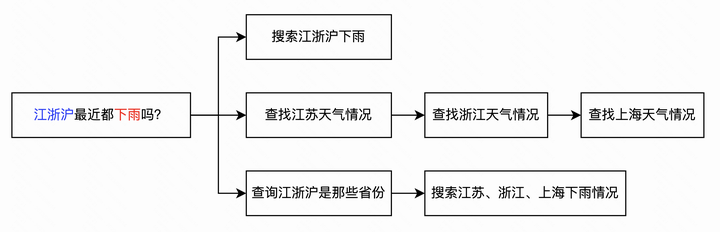
- 比如以上的例子,对于「江浙沪最近都下雨吗」这个问题,大模型通过思维链(Chain-of-thought)技术可以将任务以序列的形式进行拆分。
- 在多次调用后可以生成多条路径,也成为了一棵思维树(Tree-of-thoughts),比如针对这个问题可以直接调用搜索、分别查询三地天气或者严谨一些先验证江浙沪是什么城市在进行搜索。
- 为了提升任务成功率,我们可以采用深度优先或者广度优先等搜索方式找到一条求解路径,尽可能保证问题的解决。
2. 自我反思与批判
执行某一个子任务的时候,不一定总是能够返回想要的结果,因此模型需要有一定反思能力判断是否通过当前方式能够得到正确结果,如果不能则要动态地调整任务的序列。 ReAct (Yao et al. 2023) 发现让Agents执行下一步action的时候,加上LLM自己的思考过程,并将思考过程、执行的工具及参数、执行的结果放到prompt中,就能使得模型对当前和先前的任务完成度有更好的反思能力,从而提升模型的问题解决能力。
Thought: ...
Action: ...
Observation: ...
...(重复以上过程)
二、工具使用(Tool-use)
- 具有泛化性的工具使用能力
外部工具的使用是人、也是大模型的一种通用能力,通过工具的使用能够解决很多超出与自身知识和认知的问题,从而进一步地扩展了问题的解空间。
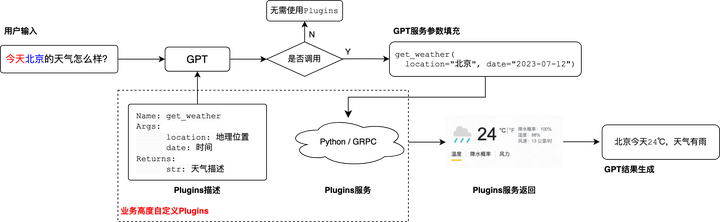
参考OpenAI的plugins技术,一般的工具使用可以分成上述流程:
(1) GPT得到需要调用的Plugins的函数信息(包括名称、描述、参数介绍等)
(2) GPT通过理解用户输入判断是否需要调用Plugins
(3) 如果判断需要调用,则同时会输出调用Plugins时所需要的参数
(4) 通过外部的python或grpc返回该Plugins的结果
(5) GPT根据结果生成用户预期的回答 因此在这个模块,如果需要支持任何种类的Plugins,则需要模型有比较强大的few-shot和zero-shot能力,在仅给予用户query和Plugins描述的情况下,自动判断是否调用、该填充什么参数等。
2. 工具集检索能力
对于平台而言,一个强大的Agents往往不会仅限于几种或几十种工具,清华最近发表的ToolLLM(Qin et al. 2023)中大模型能够使用的工具数目就高达16000+种。因此在进入大模型使用之前,我们需要从海量工具中检索得到最相关的1-5个工具。
3. 高质量的默认工具集
巧妇难为无米之炊,尽管模型学会使用工具了,但如果工具覆盖面不够广、本身返回的结果比较差,那么将会无法生成答案,甚至误导模型生成错误答案,因此需要设计一套覆盖面广的高质量默认工具集
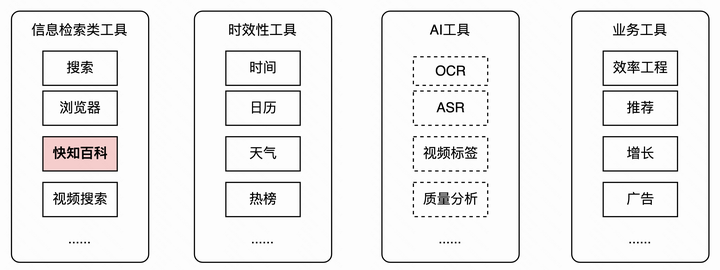
其中快知百科是我和团队在2021-2022年时期构建的亿级别规模的多模态短视频百科,目前相关的paper和部分数据已经开源,见项目地址。
三、记忆机制(Memory)
跟从人类的记忆分类,在大模型Agents中记忆也可以相应进行分类:
- 感知记忆:即刻的感官信息如视觉(图像、文字)、听觉 (语音);映射过来即多模态的即时输入,以不同种类的编码器编码成可大模型可理解的语言。
- 短期记忆:短期记忆存储着我们目前所知道的信息,以及执行复杂认知任务(如学习和推理)所需要的信息;一般来讲,短期记忆持续 20-30 秒。在大模型里其实就可以映射到 In-context Learning,即prompt的上下文长度的记忆。合理布局短期记忆能够使得模型在较高信息密度下做出最正确的决策
- 长期记忆:长时记忆可以将信息存储很长时间,从几天到几十年不等,其存储容量基本上是无限的;在大模型里可以映射到外部的数据库中的知识、历史对话,可以以计算机内存、向量数据库或者普通的数据库进行存储;目前通用的做法是使用向量进行相关内容的快速召回。
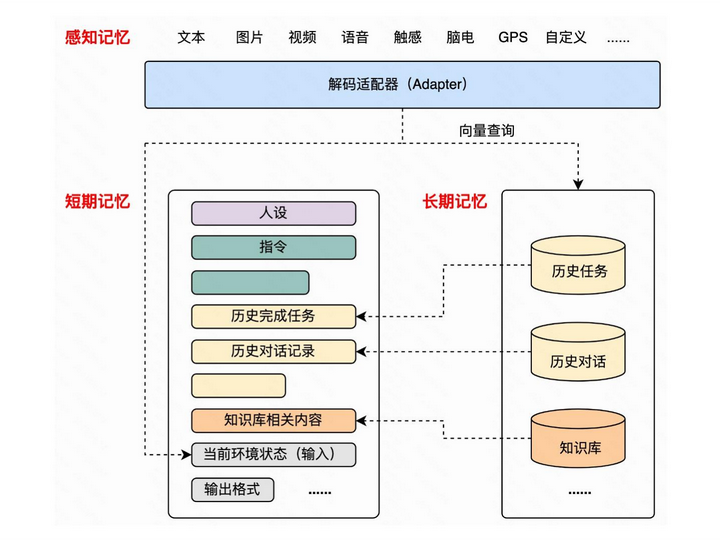
在长短期记忆中,有几块是值得单独讨论的:
- 人设:人设的定义可以比较广泛,包括性格、性别、国籍或家庭背景、处事方式、语言风格
- 指令:指令规定了这个agent是遇到对应问题都是按照哪一种逻辑和步骤进行思考,思考与执行过程中要注意的事情
- 历史任务:引入历史任务能够让Agents具备一定的反思能力,并且不会重复进行决策
- 历史对话:引入历史对话能够使得Agents具备与用户多轮对话的能力,从而对用户的意图有更好的理解
- 知识库:知识库的引入可以让Agents对专业领域的知识有一定的适配性
四、环境和执行(Environment & Action)
对于像Auto-GPT这样的纯文本交互的场景,环境(Environment)、状态(State)、行动(Action)、回报(Reward)这种强化学习Agents中常见的组成部分强调得不多。 但是随着复杂环境下Agents也慢慢能够通过大语言模型进行建模,这些就得考虑进来了。比如说Voyager这篇论文在《我的世界》游戏的探索过程中,各个组成成分分别为:
- 环境:即《我的世界》游戏的沙盒模拟器,有各种地形、草木、动物、矿产等
- 状态:状态中包含了多维度的信息,如角色的血条、饥饿值、当前地形、附近的单位(如野猪)等
- 行动:包括了一开始就会的前后左右行走,以及随着技能库更新之后的采矿、杀野猪等等
- 回报:因为不需要通过reward来调整policy,所以没有显示的局部回报,只有全局的目标(如探索更广泛的区域等)
本文其实只是单纯技术的整理和碎碎念,还没有探讨一些更深度的话题,比如“任务规划”和“工具使用”是应该拆分开来进行调用(写两个prompt),如voyager等论文,还是放在一起(写一个prompt),如ReAct的方式,目前实践上大家还没有定论,两种方式都有人在做。 但想表达的是,这个方向仍然是一个非常新兴的方向,也是我认为后续通往AGI的一条必经之路,未来肯定有更多有意思的方法和应用涌现,也希望能够推动社区对这个方向的重视。