7B的模型也能玩转AI Agents了?近期,我们开源了「KwaiAgents」,问它周末滑雪问题,它不但帮你找到场地,连当天的天气都帮你考虑周到了。

大家都知道大语言模型(LLM)通过对语言的建模而掌握了大量知识,并具备一定认知和推理能力。但即使是当前最强的GPT-4,单独使用的情况下,依然会一本正经地胡说八道,无法跟世界保持实时的交互。AI Agents就是解决这个问题的道路之一,通过激发大模型任务规划、反思、调用工具等能力,使大模型能够借助现实世界工具提升生成内容的准确性,甚至有能力解决复杂问题。这一次,我们联合哈尔滨工业大学研发的「KwaiAgents」,使7B/13B的“小”大模型也能达到超越GPT-3.5的效果,并且这些系统、模型、数据、评测,一个不差通通开源了!
从「KwaiAgents」的Github主页中可以看到,本次开源内容包含:
- 系统(KAgentSys-Lite):轻量级AI Agents系统,并配备事实、时效性工具集;
- 模型(KAgentLMs):Meta-Agent Tuning后,具有Agents通用能力的系列大模型及其训练数据;
- 评测(KAgentBench):开箱即用的Agent能力自动化评测Benchmark与人工评测结果。
系统
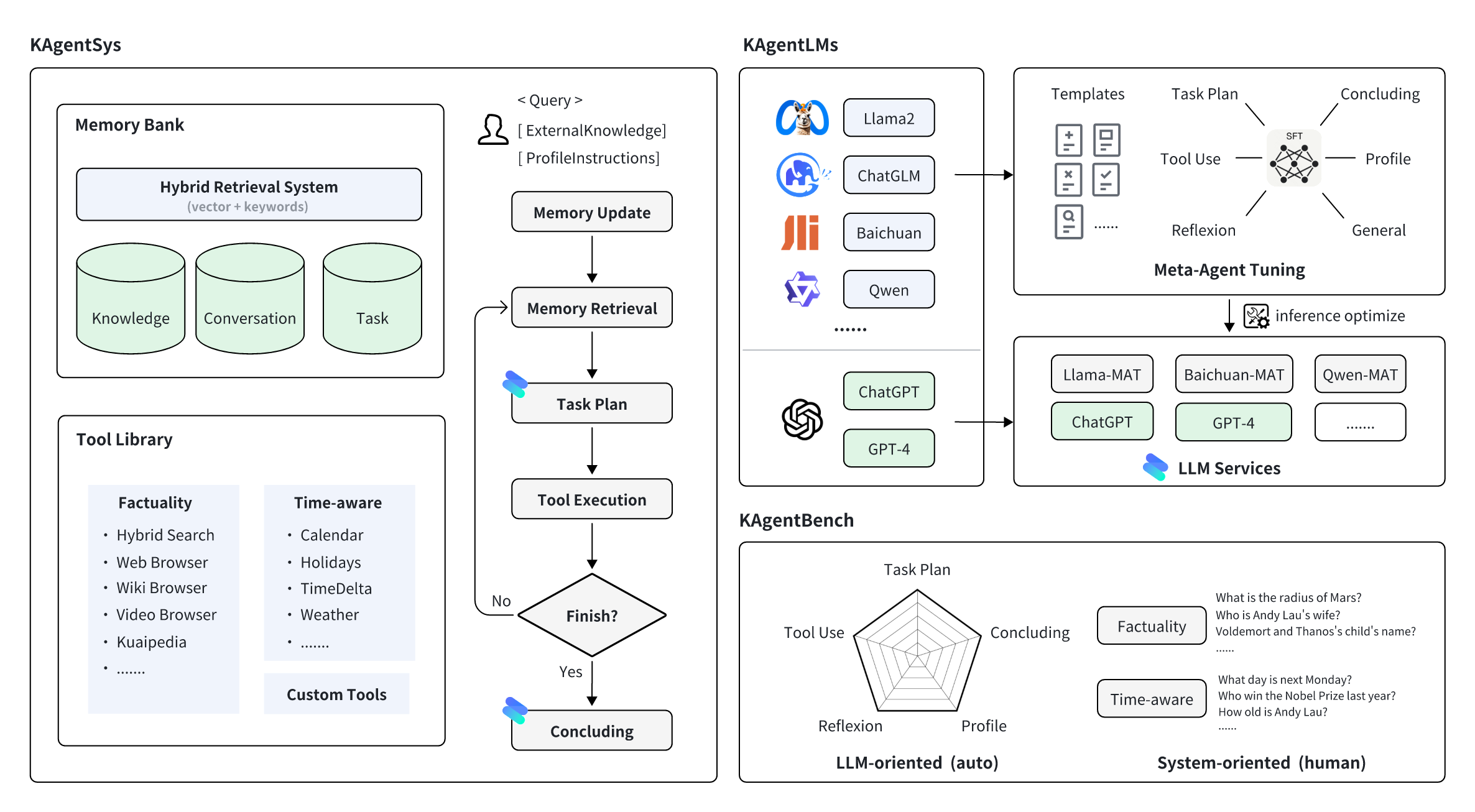
KAgentSys系统,是基于大模型作为认知内核,配以记忆机制、工具库,形成的迭代式自动化系统。其主要包含:
- 记忆机制:包含知识库、对话、任务历史三类记忆,依托于混合向量检索、关键词检索等技术的检索框架,在每一次规划路径中检索所需的信息。
- 工具集:包含事实性增强工具集,异构的搜索和浏览机制能够汇集网页、文本百科、视频百科等多个来源的知识;包含日历、节日、时间差、天气等常见的时效性增强工具集。
- 自动化Loop:在一轮对话中,用户会给予一个问题,可选知识库及额外人设整体进行输入,系统会先进行记忆的更新和检索,再调用大模型进行任务的规划,如果需要调用工具则进行调用,如果不用则进入总结阶段,大模型综合历史的信息给出符合预期的回答。
本次开源KAgentSys的部分能力,系统将逐步进行升级和开放。
模型
为了避免训练中单一模板引起的过拟合问题,团队提出Meta-Agent Tuning (MAT) 的方法,通过在训练数据中引入更多Agent Prompt模板,从而提升大模型在Agent能力上的通用性,并提升了效果。

Meta-Agent Tuning (MAT)分为两阶段:
(1)模板生成阶段:通过设计Meta-Agent,对特定问题集合,生成实例化的Agent Prompt模板(上右图为一个例子)候选;并在相同的实验环境下,生成模板产出的候选结果,与开源模板(如ReAct,AutoGPT等)产出的高置信结果,用打分模型进行对比打分,从而筛选出高质量的Agent Prompt模板库。通过引入这些多元的模板,能够显著降低模型微调时对模板的依赖,提纯更本质的Agents在任务规划、工具使用、反思等能力,从而提高模型的泛化性和有效性。
(2)指令微调阶段:基于上万的模板,构建了超过20万的Agent调优指令微调数据。团队调优了一些热门开源模型如Qwen-7B、Baichuan2-13B等,供大家使用和参考,后续还会陆续放出其他热门模型。
评测
KAgentBench通过人工精细化标注的上千条数据,做到了开箱即用,让大家能够用一行命令评测一个大模型在不同模板下,各方面的Agents能力。
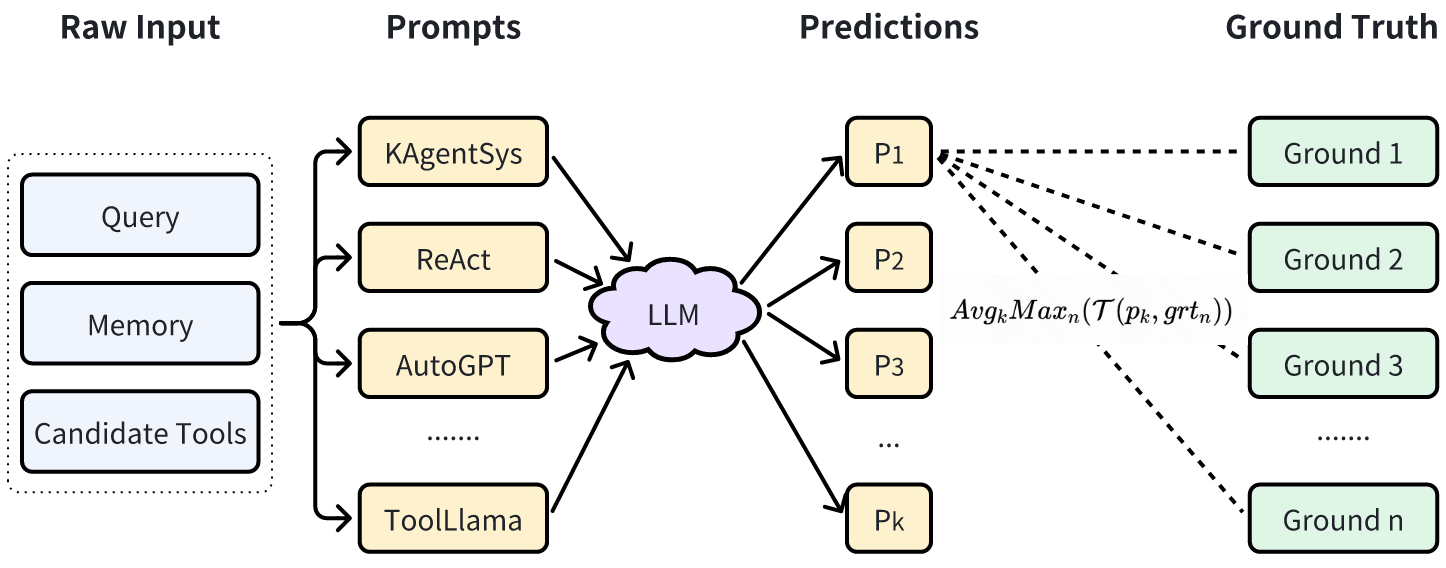
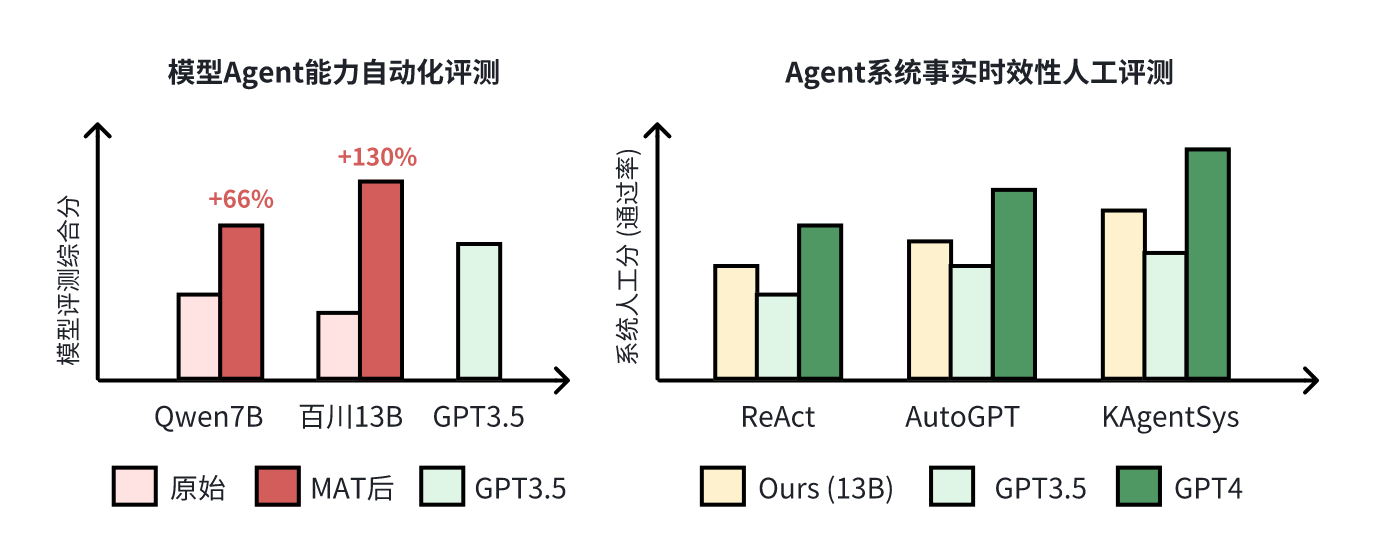
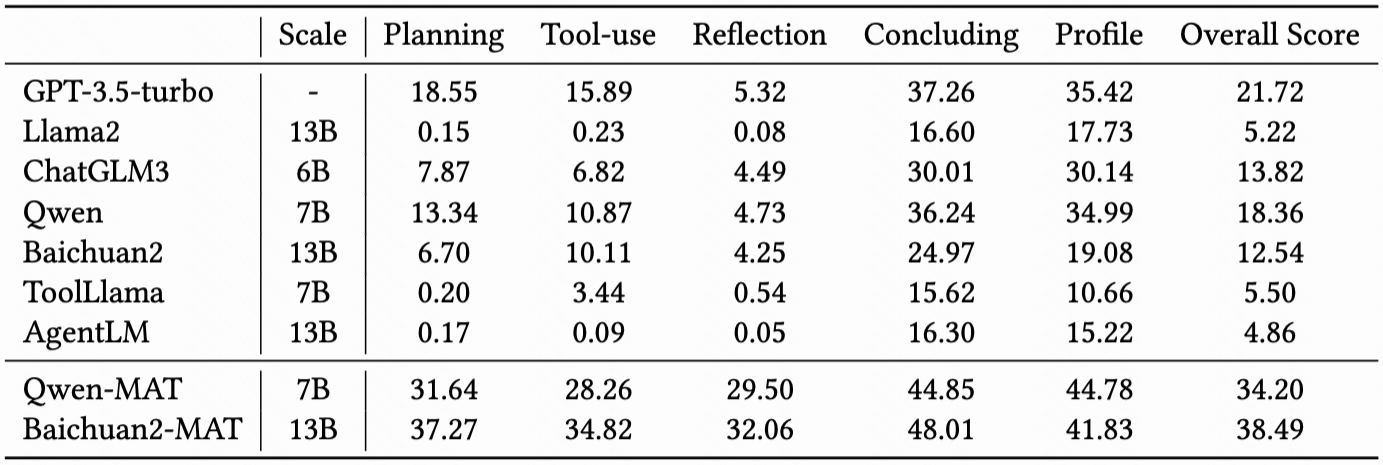
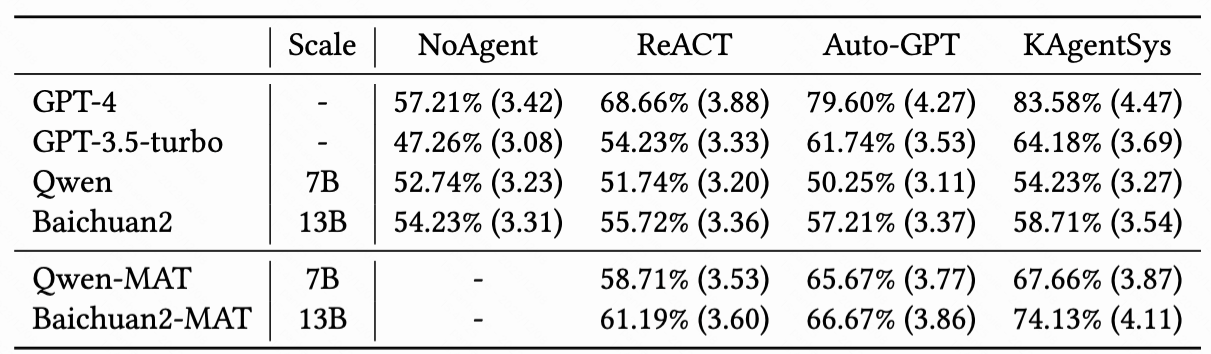
如上图所示,在KAgentBench中,会对不同种类的能力构造输入,每个query配备多个模板和多个人工编辑的真实回答,旨在综合评测准确性和泛化性,下表显示了经过MAT调优后,7B-13B模型各项能力的提升,且超越了GPT-3.5的效果:
同时,我们还请人类标注者在200个事实性和时效性的问题(如“刘德华今年几岁了”),对不同的大模型和Agent系统进行了交叉评估,可以看到KAgentSys系统和MAT之后模型提升显著(百分号前为正确率,括号内为5分制均分)。
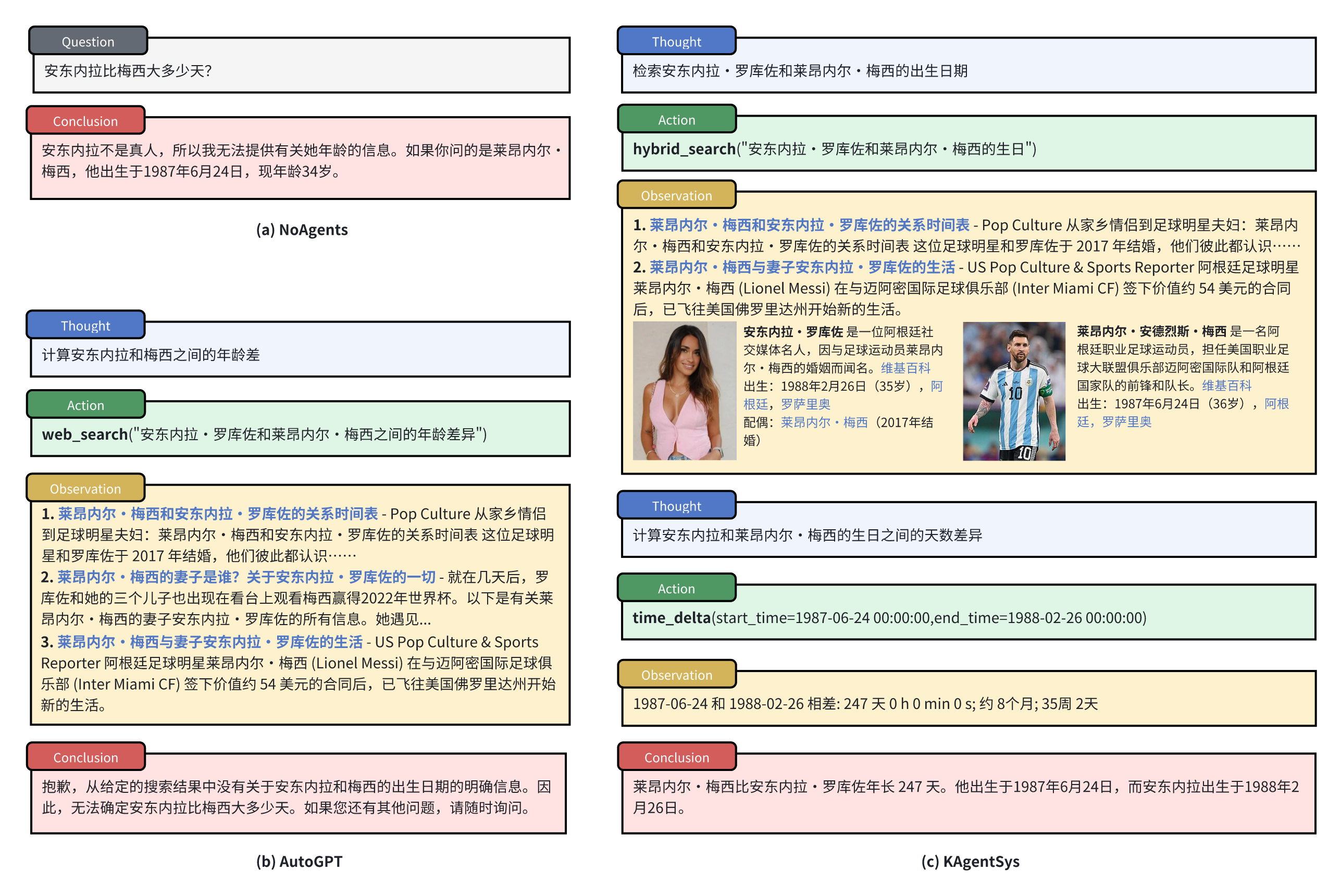
通常仅依赖网页搜索对一些长尾问题和热门问题返回结果不佳。比如问到“安东内拉比梅西大多少天?”这类长尾问题,往往搜索结果返回的都是一些两者的八卦新闻,而返回不了一些关键信息。而KAgentSys 通过调用百科搜索工具获取精准的出生日期,再调用time_delta时间差工具算出年龄差,就能精准回答这个问题了。